現在、Pythonを勉強中です。 また、生成AIも習うより慣れよと出来る限り使って経験値を高めようとしています。 ということで Gemini を教師として Python のプログラミングを学習していく過程をブログに残していきます。
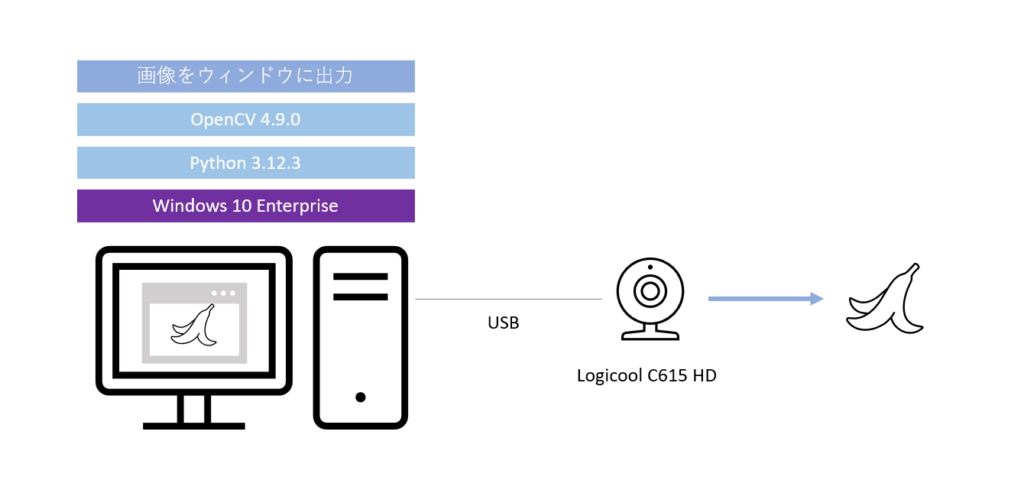
まずは Windows PC に接続された Web カメラの映像を OpenCV で取り込むプログラムを作ります。
システム構成は以下の感じです。 Windows 10 上にPython と OpenCV をインストールし、プログラムを作成していきます。
目次
Gemini に教えてもらう
opencv でWebカメラの画像をとりこむサンプルコードをおしえて

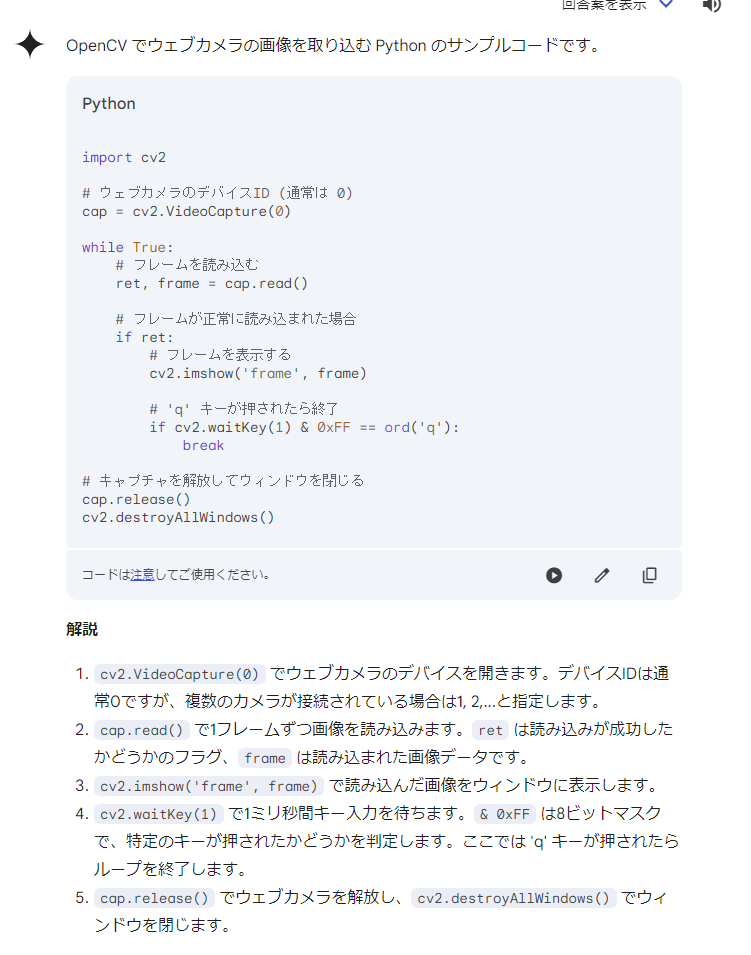
一部省略していますが上記の感じでサンプルコードと解説の答えが Gemini からかえってきました。 私の環境ではWebカメラは1つしかないのでデバイスIDは0のままで問題は出ないと考えます。だめなら 1と2と試していきます。 あと、画像の表示は cv2.imshow()で行うこともわかりました。 今回は読み込んだ画像をそのまま画面表示しますが今後画面表示ではなく書き込みするとか画像を処理するとかいろいろ試していく予定です。
コード
コメント文以外は Gemini からのサンプルコードをそのまま使います。 Gemini も Gemini以外の生成AIについても提示された生成物(コードやそれ以外も)の知財の侵害は意識する必要があります。 今回のコードは標準的なメソッド呼び出しなので知財の問題は大丈夫かなと判断しました。
import cv2
# web camera's deviceId
cap = cv2.VideoCapture(0)
while True:
# read a frame from the camera
ret, frame = cap.read()
# show the frame
if ret:
# show the frame
cv2.imshow('frame', frame)
# 'q' key is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# release the camera
cap.release()
cv2.destroyAllWindows()上記を実行すると以下のframeウィンドウがポップアップします。 窓からの風景なので個々に張り付ける前に別途モザイク処理しています。

また、このframeウィンドウの中の画像は静止画ではなく動画となっています。Webカメラで読み込まれた情報を逐次表示しているということになります。 Google Geminiからの説明通り、cap.read()で1フレームずつ読み込み、cv2.imshow()で表示し、それをbreak するまで継続処理している感じです。
2.
cap.read()で1フレームずつ画像を読み込みます。retは読み込みが成功したかどうかのフラグ、frameは読み込まれた画像データです。3.
cv2.imshow('frame', frame)で読み込んだ画像をウィンドウに表示します。4.
Google Geminicv2.waitKey(1)で1ミリ秒間キー入力を待ちます。& 0xFFは8ビットマスクで、特定のキーが押されたかどうかを判定します。ここでは ‘q’ キーが押されたらループを終了します。
まとめ
Pythonは超初心者、コーディングも日常的には行ずで C と Perl と PHP なんかは読めるけどスラスラ書くことは出来ないレベルの自分ですが Gemini を利用することで10分程度で Python と OpenCV を使った画像処理を実行することができました。
また、開発環境に Github Copilot を使っていることも大きいです。 具体的にはGithub Copilot の拡張機能をインストールした Visual Studio Code を使っていると今回のコードは最初の1文字、2文字を入力した瞬間に打ちたいコードがSuggestされるためです。 Tabキーを連続で押下していくとあっという間に書き終わります。 一応今回はコードが短いのと Python に慣れたいので1文字1文字手打ちしています。(Gemini を使わずに Github Copilot に教えてもらうという使い方も出来ますが Gemini の経験値も上げたいのであえて Gemini に聞いて、コーディングは Github Copilot にしています)
まだ1つ目のプログラミングで評価、判断するのは早計ですが生成AIに教えてもらいながらかつAI支援付きの開発環境を使うとその言語に全く慣れていないスキルレベルでも短い時間でコーディングできそうだなという感触です。
以上です