
Azure の資格を全部取得した話はこちら
Microsoft Azure について現在以下の認定を取得しています。 今回は個別の認定(DP-100 / Azure Data Scientist Associate)について認定に必要な試験 “DP-100” の話です。

私が受験したのは2020/1/5 、それから2度の試験の改訂(2020/3/22,2020/5/22)もありますが試験スキルのアウトラインを見る限り大きな変更はありません。 これから受験を予定する方に少しでも参考になればと思い試験の情報や私自身が実施した準備内容をまとめました。
目次
1. DP-100 試験の概要
試験の概要は公式ホームページを見るのが間違いないです。

“Parts of this topic may be machine translated.”とあるとおり機械翻訳で英語から日本語に変換しているので日本語がおかしいなと思ったら原文を確認しましょう。 私はいつもURLの”ja-jp” を “en-us” に手で修正しています。 Docsやその他ページで画面上に機械翻訳のON/OFF のスライドボタンを設けているページもありますが、この方法が共通で使える手順で確実かなと。
“en-us” に変更後。
試験 “DP-100: Designing and Implementing a Data Science Solution on Azure” の概要について以下の記載があります。
Azure データ科学者は、データサイエンスと機械学習に関する知識を活用して、 Azure に機械学習ワークロードを実装して実行します。特に、 Azure Machine Learning Service を使用します。これには、 Azure 上のデータサイエンスワークロードに適した作業環境の計画と作成、データ実験の実行と予測モデルのトレーニング、モデルの管理と最適化、機械学習モデルの生産への展開が含まれます。
上記の文章を初めて読んだときは正直ピンときませんでした。試験の概要というよりは Azure 上でMachine Learning Service の利用の概要です。
同じホームページ内の”評価されるスキル”に列挙されている項目とアウトライン資料のほうが受験者への要求が具体的です。 PDF資料は上記のホームページにダウンロードリンクがあります。 こちらは必読な内容になります。

2. 試験のアウトライン
ただ”Exam DP-100: Designing and Implementing a Data Science Solution on Azure – Skills Measured”を読んでくださいだと不親切ですのでガイドのPDF資料の内容を簡単にまとめます。 もとのガイドは英語なので日本語でまとめてみました。 訳さない方がよい部分は意図的に英語のままにしています。
2.1. Audience Profile (受験者のプロフィール)
まず以下の知識を前提としてもっていること。
- Data science と Machine Learning の実装に関する知識
- Azure Machine Learning Service 上でワークロードを実行出来る知識
- ワークロード実行環境の作成、予測モデルのトレーニングなど
2.2. Skills Measured (スキルの測定)
試験で測定されるスキル(試験の範囲)について2点ほど注意書きがあります。
- 箇条書きは試験の対象スキルとなるが完全なものではないよ
- プレビュー機能など試験の対象外だよ
1つ目の”箇条書き”はアウトライン資料の以下の赤枠のことと考えます。 試験範囲として具体例をリストしている、ただし、これが全てではないよ、これ以外のことも試験には出るよ、ということです。 まあ、これはMCPでも他のどんな試験でも試験のアウトラインはアウトラインでしかないのであまり気にする必要はないでしょう。

ここからは具体的なSkill Measured についてです。
Set up an Azure Machine Learning workspace (30-35%)
Create an Azure Machine Learning workspace
- Azure Machine Learning workspace の作成
- workspace の設定
- Azure Machine Learning Studio によるworkspace の管理
Manage data objects in an Azure Machine Learning workspace
- data stores の登録とメンテナンス
- datasets の作成と管理
Manage experiment compute contexts
- 仮想マシンインスタンスの作成
- ワークロードに適した仮想マシン仕様の選定
- compute targets の作成
Run experiments and train models (25-30%)
Create models by using Azure Machine Learning Designer
- training pipeline の作成
- Designer pipeline へのデータ挿入
- pipeline データフローを定義するためのDesigner modules の使用
- カスタムコードモジュールの使用
Run training scripts in an Azure Machine Learning workspace
- Azure Machine Learning SDK によるexperiment の作成と実行
- SDK によるdata store からのデータ利用
- SDK によるdataset からのデータ利用
- estimator の選択
Generate metrics from an experiment run
- experiment の実行からのlog metrics
- experiment の結果の取得と表示
- ログを使用したトラブルシューティング
Automate the model training process
- SDK によるpipeline の作成
- pipeline の step 間でのデータの受け渡し
- pipeline の実行
- pipeline の実行の監視
Optimize and Manage Models (20-25%)
Use Automated ML to create optimal models
- Azure Machine Learning studio の Automated ML interface の使用
- SDKからのAutomated ML interface の使用
- scaling functions とpre-processing options の選定
- 検索アルゴリズムの決定
- 主要なmetric の定義
- 実行したAutomated ML からのデータの取得
- 最適なmode を取得する
Use Hyperdrive to tune hyperparameters
- sampling method の選定
- search space の定義
- 主要なmetric の定義
- early termination options の定義
- 最適な hyperparameter values を持つモデルを見つける
Use model explainers to interpret models
- model interpreter の選択
- 重要な特徴量データの生成
Manage models
- トレーニング済モデルの登録
- model history の監視
- data drift の監視
Deploy and Consume Models (20-25%)
Create production compute targets
- 展開されたサービスに関するセキュリティの考慮
- 展開のためのCompute options の評価
Deploy a model as a service
- deployment settings の構成
- 展開されたサービスの消費
- doployment container のトラブルシューティング
Create a pipeline for batch inferencing
- batch inferencing pipeline の公開
- batch inferencing pipeline の実行と結果の取得
Publish a designer pipeline as a web service
- ターゲットとなるcompute resource の作成
- inference pipeline の構成
- 展開されたエンドポイントの消費
2.3. 試験の改訂について
アウトライン資料”Exam DP-100: Designing and Implementing a Data Science Solution on Azure – Skills Measured”には2回の改訂、2020/3/22 と2020/5/22 の改訂について履歴の記載があります。 結論から言うと試験のアウトラインに変更はないようです。 スペルの綴りの変更や略語を正式名にするなど表現に関する改訂だけでした。
3. 試験の対策
どんな問題が出たかは規約上書けません。 自分の受験時のスキルレベル、どんな対策を行ってそれがどう効果的だったか、効果があまりなかったか、などを書いていきます。
3.1. 当方のスキル、経験
Data Science に関する業務経験、スキル
- 実業務としてはほぼ無し。 10年前ほどにInstitutional Research に関するプロジェクト参画の中で基本的な概念などに触れたことがある程度。
- 大学等での研究、専攻なども無し
- 書籍は多少読んでいた (後ほど紹介)
- Data Science の実行環境の導入に携わった経験は多少あり
Microsoft Azure に関する知識
- セールス、デリバリー経験は2年弱
- 色々なAzure 認定は持っているが素人レベル
- Azure Machine Learning に関する実業務での経験は無し
その他業務経験、スキル
- SE 経験は約20年、17年はアカウントSE
- パブリッククラウドに特化して約3年
- パブリッククラウドはAlibaba Cloud 、Microsoft Azure 、GCPなど。
- レガシーシステムは全領域OK
- 開発はスクリプト、シェルまで
簡単に言えばデータサイエンティストとしての経験はなし、データサイエンスの実行環境の構築の経験、PJへの参画の経験は多少あり、という感じです。
Azure は資格は持っていますが内実は素人。触っている絶対量が少ない。
ただ、レガシーシステムは全領域やっていたので今のパブリッククラウドのIaaS / PaaS / SaaS の機能のほとんどは自分自身で提案や設計、構築していたことがあります。 お客様と一緒に何でも自由に実現できたオンプレに対して、型が決まったパブリッククラウドはある意味覚えなきゃいけないことは少ないなぁ(何が出来ないかだけ注目)と普段感じていたり。 なのでAzure が素人なのは確かなのですが、その中身はわかっているという感じです。
3.2. 試験の対策
試験の範囲を確認する
他の試験同様にアウトラインで試験範囲を確認しました。 確認して最初に感じたのは準備無しでは合格できないな、と。
試験範囲を抜粋すると以下の4区分です。
- Set up an Azure Machine Learning Workspace (30-35%)
- Run Experiments and Train Models (25-30%)
- Optimize and Manage Models (20-25%)
- Deploy and Consume Models (20-25%)
簡単に言えば Azure Machine Learning を使えること、環境をデプロイし、実際にモデルを作り、トレーニングし、結果を評価する、と。 なのでAzureの関連プロダクトの操作のスキルは必要なことがわかります。 また、その前提にあるのはMachine Learning に関する知識です。 Azure に関係なく概念や用語を理解している必要があります。
一方、私は Azure Machine Learning を使ったことはありませんでした。 Machine Learning については多少書籍で知恵はつけていました。
私は資格試験を受けるときは基本準備無しで受けることがほとんどです。 受けてみることで弱点やどんな問題が出るかわかるため。 とはいいつつ今回の試験は準備無しでは何がわからないのか、それすらわからなかったとなることが目に見えていました。 準備することにしました。
Microsoft Docs を確認する
まずは Microsft Docs でマニュアルを読みます。
結構な分量がありますが暗記するわけではないので流し読みです。 Azure Machine Learning でどんなことが出来るのか把握できればOKという感じです。 わからないところは飛ばしつつ1時間位と時間を決めてでひととおり眺めました。 その時、Machine Learning に関する用語、概念などで不明なものは手元の紙に書きだしておきます。 それは別途、書籍や本で確認しておきました。
マニュアルを読むことで Azure Machine Learning で出来ること、出来ないこと、登場人物(実際はモノではなくVirtual Machineなど他に関連してくるサービスなど)を把握できます。 また、どんな情報がマニュアルにあったかざっくりと頭に残しておくことで後で調べ物をするときに役立ちます。
また、読む前からわかっていたことですが、アウトラインにもあるAzure Machine Learning の操作はマニュアルだけだとイメージを掴むのが大変です。 ものによってはマニュアル内に画面付きの手順は紹介されています。
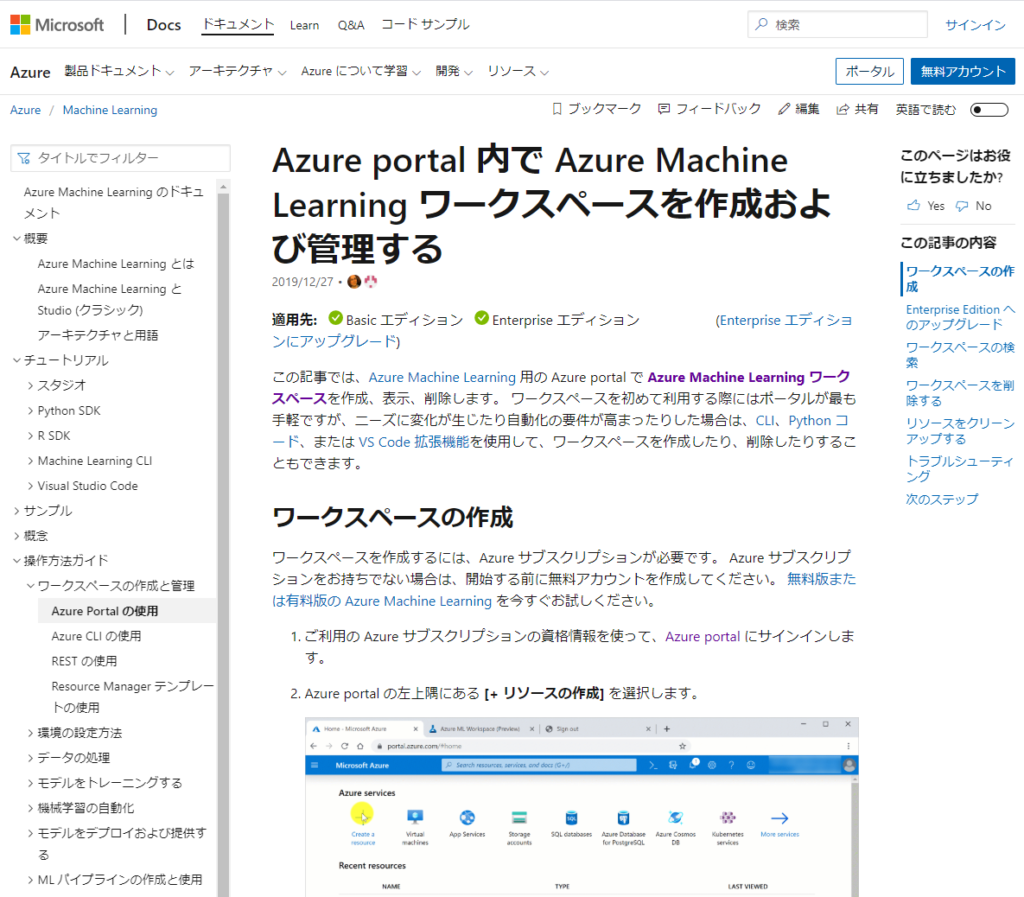
ただ、マニュアルの場合、連続性がありません。 何を言っているかというと、マニュアルはチュートリアルと違い、各種情報がインデックスの観点で並んでいます。 例えば以下のスクリーンショットではワークスペースの作成と管理の情報は”Azure Portalの使用” にあることが階層化された項目で提供されています。 知りたい情報が明確な場合はこの提供形態が最適です。 しかし、順番に次の項目に進むと”Azure CLIの使用”となり、ワークスペースを作成するという同じ目的について異なる方法が提示されます。 今回のようにサービスを触ったことがなくとりあえず一覧の流れを手っ取り早く知りたいという使い方には向かないということです。
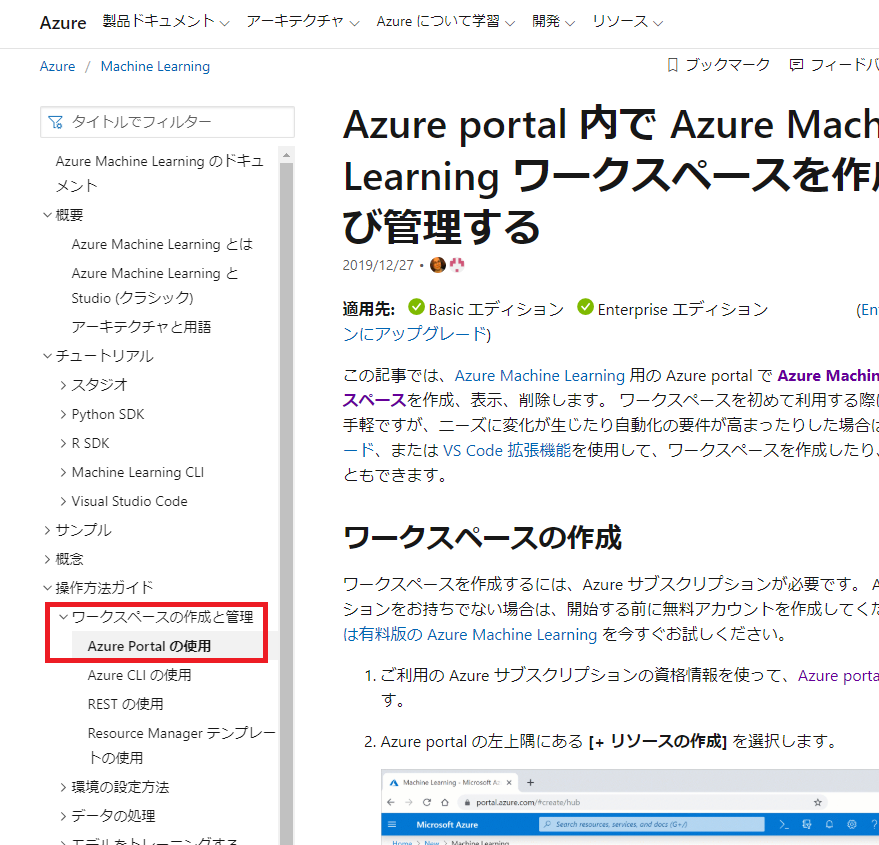
とは言いつつ、Azure のプロダクトでもチュートリアルが提供されているDocs も沢山あります。 この Azure Machine Learning もそうです。
ワークスペースの作成から始まり、
モデルをトレーニングしたり、最後は予測モデルのデプロイまで丁寧に紹介されています。
チュートリアルを実行する
読むだけでも良いのですが眠くなる&覚えにくいので実際にやってみます。 確か2時間くらいで一通り出来たはず。 これでアウトラインで試験範囲とされた一連の流れは把握出来ました。 あっさりと書いていますがこれはやっておいた方がよいです。
本を読む
Cognitive Services入門 マイクロソフト人工知能APIの使い方
何かでもらった本。 中身はCognitive Services なので今回の試験の対象とはちょっと違う。 間接的なという意味で読んでおいて損はありませんが必須ではないです。 AI-100 のときに役立つ本です。

ここからは私が使っている電子書籍サービス “Honto” で買って読んだものを紹介します。 ただ、今回の試験のために買ったわけではないので過去に読んでいたものという感じです。
さわってわかる機械学習Azure Machine Learning実践ガイド
2016年の本で古いのですが、Azure Machine Learning を知るにはちょうど良いです。 当たり前の話ですが書籍は読みやすいものです。 知りたいことが明確な場合はマニュアルも良いのですが0から全体を抑えようと思うとマニュアルはその構造的に向かないことが多く。
実践ガイドとなっていますが前半は機械学習の一般論から始まります。 次にデータの集め方、その上でAzure Machine Learning を使った実践に入ります。 実践では学習モデルを作り、回帰分析による予測やクラスタリングなどをチュートリアルの形で実践することが出来ます。

60分でわかる!機械学習&ディープラーニング超入門
超入門とありますがお勧めです。 最低限知っておくべき用語や概念などが良い意味でシンプルに説明されており頭にいれやすかったです。 また、世の中の適用事例、適用シーンが多く(20個ほど)紹介されておりそれもよかったです。 2017年発売なので似たようなコンセプトの本でもよいかもしれません。

いちばんやさしい人口知能ビジネスの教本
上の本と近いコンセプトを持つ本ですが、ビジネスへの適用という切り口でまとめられています。 試験という意味では上のものかこちらかどちらかで概念を把握するのはよいと思います。

ITエンジニアのための機械学習理論入門
機械学習のアルゴリズムを知る上でお勧めです。
2015年とちょっと古いです。購入も大分前です。 上の超入門に対してこちらも入門とありますがアルゴリズムや理論に関する入門で私にはとても入門とは言えない中身の濃さ。 アルゴリズムや理論を数式とともに丁寧に解説されています。 導入部分にも書いてあるのですが機械学習の理論を知らずとも使えてしまう現状への危惧、出来合いのAIサービスにデータを投入するとそれらしい結果が出てくること、へしっかりとアルゴリズムを理解しないとそのようなデータには意味がないという著者の思いが伝わります。 具体的には以下のアルゴリズムについて知ることができます。
- 最小二乗法
- 最尤推定法
- パーセプトロン
- ロジスティック回帰とROC 曲線
- k 平均法
- EM アルゴリズム
- ベイズ推定

フリーライブラリで学ぶ 機械学習入門
2017年発売。 こちらも入門です。 中身はPythonで実際にモデルを作ったり、クラスタリング分類したり、画像認識したり、ディープラーニングしたり、初学者向けのチュートリアル的な流れで機械学習を理解しつつ手を動かせます。とは言いつつ私はざっと読んだだけですが。

他にも3-4冊程度。
4. まとめ
試験の概要と私の準備内容を紹介しました。 試験自体はAssociate クラスなので難しい内容はありません。 基礎・基本が問われるものが多かった印象です。 おそらくPythonで自分で予測モデルを作っているエンジニアであれば一度 Azure Machine Learning のチュートリアルをやるだけで合格するのかなと。 私は機械学習は経験がなかったのでマニュアル読んだり書籍での学習が必要でした。 ちゃんとは覚えていませんが学習時間は3-4時間位だったと思います。
この認定を取得するメリットは Azure Machine Learning で出来ることを具体的に把握できることにあります。 なのでデータサイエンティストな属性の方がAzure のMachine Learning を使えるよと対外的に示すのによいかなと。
一方、当方のように非データサイエンティストな場合に意味がないかというとそのようなことはないと考えています。 プリセールスの場面など、Azure Machine Learning を使いたいと考えているデータサイエンティストにAzureで出来ること出来ないことを適切に説明できるためです。 まあ、データサイエンティストがAzure のマニュアル読めば済む話のように思えますが世の中には沢山のクラウドサービスがあるなか、他のクラウドでのMLサービスとの違いや手作りの環境踏まえてAzureの良さを伝えられることが目指すところかなと、今現在は考えています。 そのように思えるようになったことが私自身にとってはメリットでした。
以上

